
除了Redis可以实现分布式锁之外,还可以通过Zookeeper实现,它较于前者的优势是它的数据是强一致的,一般秒杀会用到。今天我们来介绍一下基于ZooKeeper实现分布式锁。😄
首先在介绍ZooKeeper实现分布式锁之前,先介绍一下ZooKeeper遵循的一个ZAB协议。专为 ZooKeeper 设计,用于在分布式系统中实现原子广播和崩溃恢复。ZAB 协议的核心目标是确保所有节点在数据更新时保持一致,同时保证系统的高可用性和分区容错性。
ZAB协议
核心目标
原子广播
其实就是原子性(大雾,所有写操作(如创建节点、修改数据)必须被所有节点成功接收,或者全部失败。
顺序一致性
所有节点的数据更新顺序必须严格一致。
崩溃恢复
如果 Leader 节点挂了,能快速选出新 Leader,并恢复数据一致性。(如果老板倒了,快速选新老板,对照员工的数据恢复,保证数据的一致性)
工作模式
有两种工作模式。
崩溃恢复模式
所有节点(Follower)投票选一个新 Leader(类似选班长)。后面会说选举的具体过程。
新 Leader 会检查所有节点的数据,确保大家的数据一致(同步最新状态)。
同步完成后,集群进入消息广播模式。
消息广播模式
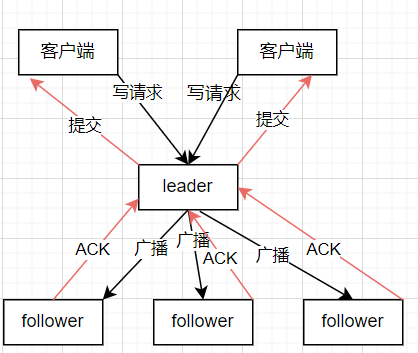
客户端发送写请求(比如创建节点)给 Leader。
Leader 把写操作包装成一个 Proposal(提案),按顺序广播给所有 Follower。
Follower 收到后,先回复 ACK(确认),但不立即执行。
当超过半数 Follower 确认后,Leader 发送 Commit 命令,大家才真正更新数据。
关键点:
只有 Leader 能处理写请求(避免冲突)。
写操作必须按顺序执行(防止数据错乱)。
在实现分布式锁之前,还需要知道在Zookeeper中的几个核心概念,才能对后续实现有所了解。
数据一致性保持
两阶段提交
阶段1(Proposal):Leader 广播提案,Follower 只记录但不执行。
阶段2(Commit):收到多数派确认后,Leader 才通知大家真正提交。
事务ID(ZXID)
每个写操作都有一个全局唯一的 ZXID(类似版本号),一个64位的整数,由两部分组成:
epoch:前32位,Leader 的任期编号(换届时递增)。
counter:后32位,在这个周期内leader进行了多少次事务操作(每次新选举就 +1)。
作用:确保所有节点按相同顺序执行操作。
核心概念
ZNode: ZooKeeper 存储数据的节点,类似于文件系统中的文件或目录。
临时节点(Ephemeral Node): 客户端会话结束后,节点会自动删除。
顺序节点(Sequential Node): 节点名称会自动附加一个递增的数字后缀。
Watcher: 监听 ZNode 的变化(如创建、删除、数据更新等),并触发回调。
可以这么想,zookeeper相当于是在一个热门的餐馆店排队的管理者。
然后znode就相当于是显示屏,显示当前的排队情况。
临时节点就相当于排队的那个小票,上面一般会标记一个排队号。
顺序节点就是说每个人取的号是递增的,先到先到。
watcher就相当于广播,盯着当前最小的顺序节点,只要它被删除,你就喊下一个快点上去。
现在我们知道了Zookeeper的核心概念了,那么就要去了解它到底是怎么实现的分布式锁了,接下来主要介绍实现的原理。
实现原理
临时顺序节点
临时顺序节点=临时节点+顺序节点
特点:
临时性
顺序性
唯一性
Watcher机制
ZooKeeper 提供的一种事件通知机制。客户端可以在某个 ZNode 上注册一个 Watcher,当该 ZNode 发生变化时(如创建、删除、数据更新等),ZooKeeper 会通知客户端。
特点:
一次性
异步
可以监听多种事件
接下来具体说明实现的流程了。
实现流程
创建一个节点lock作为锁的根节点,当有线程需要抢锁的时候在该节点下创建一个临时有序节点创建临时顺序节点。
获取创建的lock的所有子节点,并按照顺序排序,是最小的就获得锁,不是就监听前一个节点的删除事件。
业务逻辑完成后,删除创建的临时节点,通知下一个序号的节点,让它得到锁
根据实现的流程就能知道,使用zookeeper不会造成死锁,还会自动释放锁,同时数据也是强一致的。
ZAB选举leader
zookeeper中有三种节点,leader,follower,observer(不参与选举)。
集群启动时,会选举,然后leader挂了也会选举。
如果 Leader 挂了,集群会暂时不可写(但可读),必须快速选一个新 Leader 出来,否则整个系统就卡住了。
这里因为只去了解了快速选举的算法,就先介绍快速选举,后续增加。😎
核心规则
比较ZXID,节点的ZXID大就投票给它,相同的话,就在去比较myid,也是谁大投谁。然后能投票给自己或其他的节点,投票的信息有ZXID,myid,epoch。
选举流程
初始化所有节点都进入LOOKING状态
每个节点首先投票给自己,然后广播投票信息给其他节点
节点接收其他节点的投票信息,根据选举规则比较投票信息
节点统计收到的投票信息,判断是否有节点获得了超过半数的投票,如果有,选举结束,它就是leader了☝️
新leader向其他节点发送确认信息,其他节点收到信息后,进入FOLLOWING状态,成为follower
leader处理请求,广播到follower🤝
评论