
类加载器
类的加载过程:加载 -> 连接 -> 初始化
连接过程:验证 -> 准备 -> 解析
加载过程:获取类的二进制字节流 -> 转换字节流的静态存储结构为运行时数据结构 -> 内存中生成一个class对象,作为数据的访问入口
作用:动态加载 Java 类的字节码( .class 文件)到 JVM 中(在内存中生成一个代表该类的 Class 对象)。
分类
BootstrapClassLoader(启动类加载器):最顶层的加载类,C++实现,通常为null,并且没有父级,主要加载JDK 内部的核心类库以及被 -Xbootclasspath参数指定的路径下的所有类。
ExtensionClassLoader(扩展类加载器):主要负责加载 %JRE_HOME%/lib/ext 目录下的 jar 包和类以及被 java.ext.dirs 系统变量所指定的路径下的所有类。
AppClassLoader(应用程序类加载器):面向我们用户的加载器,负责加载当前应用 classpath 下的所有 jar 包和类。
除了这三种,还存在一种自定义类加载器。
自定义类加载器:继承ClassLoader抽象类,打破双亲委派模型重写loadClass方法,不打破就重写findClass()方法。
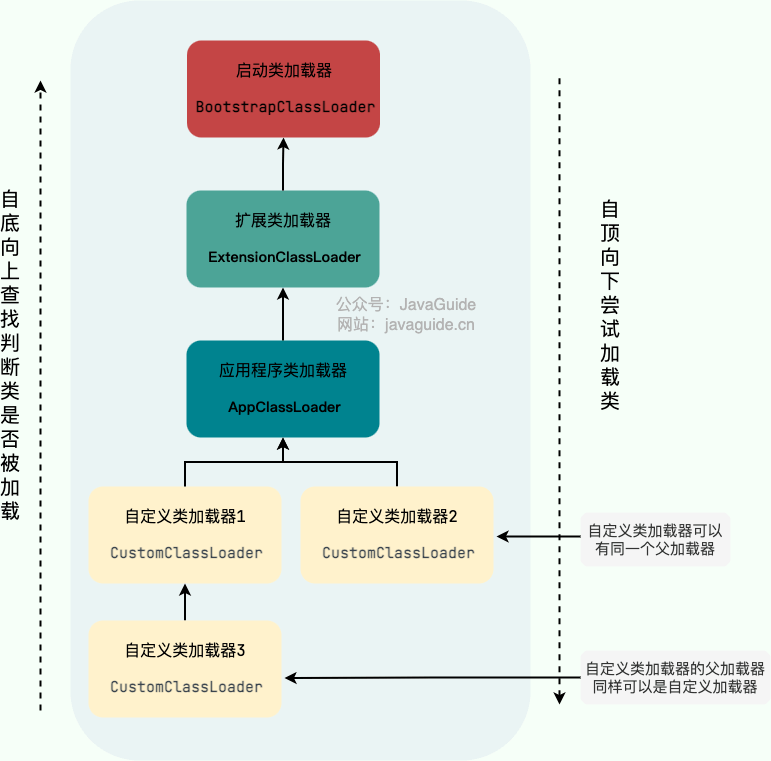
除了 BootstrapClassLoader 是 JVM 自身的一部分之外,其他所有的类加载器都是在 JVM 外部实现的,并且全都继承自 ClassLoader抽象类。这样做的好处是用户可以自定义类加载器,以便让应用程序自己决定如何去获取所需的类。
双亲委派机制
自底向上委托:当一个类加载器需要加载某个类时,它首先不会自己去尝试加载,而是把这个请求委托给父类加载器去完成。
自顶向下查找:只有当父类加载器反馈自己无法完成这个加载请求时(即它的搜索范围中没有找到所需的类),子类加载器才会尝试自己去加载。
递归过程:这个过程是递归的,直到启动类加载器(Bootstrap ClassLoader)为止。
[加载请求]
↓
[应用程序类加载器] → 委派 → [扩展类加载器] → 委派 → [启动类加载器]
↑ (父加载失败) ↑ (父加载失败) ↓ (尝试加载)
│ │ ↓
│ └── 扩展类加载器尝试加载
│
└── 应用程序类加载器尝试加载运行时数据区
方法区
存储类的信息、运行时常量池
常量池的特点
编译器生成
内存共享
动态链接
内存回收
堆
定义
存放所有的对象实例和数组
线程共享的内存区域
由垃圾回收器CG管理
特点
线程共享
动态分配
内存不连续
垃圾回收
结构
新生代
Eden区:新创建的对象首先放在这里
Survivor区:存放从Eden区经过一次GC还存活的对象
Minor CG区:新生代的垃圾回收
老年代
对象在新生代经过多次GC还存活就移动到老年代
Major GC/Full GC:老年代的垃圾回收
元空间
存放类的元数据
不在堆中,使用的是内存
Java8之前叫永久代
配置参数
-Xms:堆的初始大小
-Xmx:堆的最大大小
-XX:NewRatio:新生代与老年代的比例
-XX:SurvivorRatio:设置Eden区与Survivor区的比例
存在问题
堆内存可能会不足
GC频繁
内存泄漏
栈
定义
线程私有的内存区域
存储方法调用的栈帧,存储局部变量、操作数栈、动态链接和方法返回地址等信息
特点
线程私有
栈帧结构
FIFO
内存有限
结构
局部变量表:存储方法的参数和局部变量
操作数栈:执行字节码指令时存储操作数
动态链接:指向运行时常量池的方法引用
方法返回地址:方法执行完毕后返回到哪里
配置参数
-Xss:线程的栈大小
本地方法栈
本地方法,一个Java调用非Java代码的接口
程序计数器
记录当前线程正在执行的字节码指令的地址
特点
线程私有
不会溢出
不涉及垃圾回收
执行引擎
将字节码解释或编译成机器码,并执行这些指令
解释器:逐行把字节码翻译成机器码并执行
JIT编译器:把热点代码(频繁执行的代码)一次性编译成机器码,效率更高
本地方法接口
Java调用本地方法(如C/C++代码)的接口
本地方法库
用其他语言(如C/C++)编写的库,供Java程序调用
垃圾回收
用于回收内存不再使用的对象占用的内存空间,避免内存泄漏。
原因
如果一个或多个对象没有任何的引用指向它了,那么这个对象现在就是垃圾,如果定位了垃圾,则有可能会被垃圾回收器回收
垃圾对象的判定
可达性分析算法
从根对象出发,遍历所有可达对象,不可达的对象视为垃圾。
引用计数法
每个对象去维护一个计数器,记录被引用的次数,当次数变为0,对象就被视为垃圾,缺点就是无法解决循环引用问题。
回收算法
标记清除法
从 GC Roots 出发,标记所有可达对象,遍历堆内存,回收未被标记的对象
复制算法
把堆内存分为两块(From和To),将from的存活对象复制到to区,然后清除from区的所有对象。
标记整理算法
从 GC Roots 出发,标记所有可达对象,将存活对象向内存的一端移动,清理剩余内存
分代回收
低存活率的新生代复制算法,高存活率的老年代标记清除法或者标记整理法。
finalize 方法
子类可以重写它来定义对象被回收前的清理逻辑
每个对象的 finalize 方法只会执行一次
第一次被标记为不可达时,finalize 方法被执行,并且在该方法中将对象重新与 GC Roots 关联
第二次被标记为不可达时,finalize 方法不会再次执行,对象会被直接回收
引用类型
强引用:有用且必须
弱引用:可能有用且非必须
软引用:有用且非必须
虚引用:无用
垃圾回收器
Java垃圾回收器是JVM自动内存管理的核心组件,负责回收不再使用的对象以释放内存。以下是主流垃圾回收器的分类和特点:
按代际划分的垃圾回收器
1. 新生代回收器
Serial收集器
单线程STW(Stop-The-World)工作
适合客户端应用,简单高效
使用复制算法(Copying)
ParNew收集器
Serial的多线程版本
与CMS配合工作的首选新生代收集器
默认线程数=CPU核心数
Parallel Scavenge收集器
吞吐量优先(Throughput)
自适应调节策略
适合后台运算型应用
2. 老年代回收器
Serial Old收集器
Serial的老年代版本
使用标记-整理算法(Mark-Compact)
作为CMS失败时的后备方案
Parallel Old收集器
Parallel Scavenge的老年代版本
多线程标记-整理算法
JDK6开始提供
CMS(Concurrent Mark-Sweep)收集器
以最短停顿时间为目标
四阶段过程:
初始标记(STW)
并发标记
重新标记(STW)
并发清除
缺点:内存碎片问题
3. 全堆回收器
G1(Garbage-First)收集器
JDK9默认收集器
将堆划分为多个Region(默认2048个)
可预测的停顿时间模型
混合回收策略(Young GC + Mixed GC)
ZGC(Z Garbage Collector)
JDK11引入(生产环境从JDK15开始)
目标:<10ms的STW停顿
关键技术:着色指针(Colored Pointers)和读屏障
支持TB级堆内存
Shenandoah
与ZGC竞争的低延迟收集器
并发压缩算法
通过读/写屏障实现并发
核心算法对比
关键参数配置
// 常用JVM参数示例
-XX:+UseSerialGC // 使用Serial+Serial Old组合
-XX:+UseParNewGC // 使用ParNew+Serial Old组合
-XX:+UseParallelGC // 使用Parallel Scavenge+Parallel Old
-XX:+UseConcMarkSweepGC // 使用ParNew+CMS+Serial Old
-XX:+UseG1GC // 使用G1收集器
-XX:+UseZGC // 使用ZGC(JDK11+)
-XX:+UseShenandoahGC // 使用Shenandoah(需单独版本)
// 通用调优参数
-Xms4g -Xmx4g // 堆大小(生产环境建议设为相同值)
-XX:NewRatio=2 // 新生代:老年代=1:2
-XX:SurvivorRatio=8 // Eden:Survivor=8:1:1
-XX:MaxGCPauseMillis=200 // 目标最大GC停顿时间(ms)选择策略
吞吐量优先:Parallel Scavenge + Parallel Old
适合后台计算型应用
示例:大数据处理、科学计算
低延迟优先:CMS/G1/ZGC/Shenandoah
适合交互式应用
示例:Web服务、交易系统
小内存应用:Serial + Serial Old
适合客户端程序
示例:桌面应用、移动应用
超大堆内存:G1/ZGC/Shenandoah
堆内存>4GB时建议使用
特别推荐ZGC用于TB级堆
建议通过
-XX:+PrintGCDetails和可视化工具(如GCViewer)分析实际应用的GC日志,针对性地选择最适合的回收器组合。
评论